
Requests for Adminship on Wikipedia
The Request for Adminship (RfA) process is a pivotal aspect of Wikipedia’s community-driven governance. It is the procedure through which contributors nominate themselves or others to gain administrative privileges, granting access to critical tools for maintaining the quality and integrity of Wikipedia. However, the decision to grant adminship is not taken lightly and relies on a rigorous vetting process.
Project overview: analyzing RfA votes
Our project explores the dynamics of the RfA process through a comprehensive analysis of voting patterns and outcomes. Using a dataset containing all votes cast between 2003 (when the RfA process was adopted) and May 2013, we aim to uncover insights into the social and structural aspects of Wikipedia’s governance.
The dataset
The dataset, meticulously crawled and parsed, includes:
- 198,275 total votes cast across 189,004 unique voter-votee pairs.
- 11,381 users involved in the process as voters or candidates.
- Multiple RfA attempts by some candidates, allowing us to analyze repeated patterns of support or opposition.
Data augmentation
To better categorize users, we augmented the dataset by scraping additional data from Wikipedia. Specifically, we extracted the “admin score” of each user from xTools and the 10 most edited pages for each user, providing valuable context about their areas of contribution and expertise.
How are RfAs decided?
Although the RfA process allows any Wikipedia member to vote (support, oppose, or remain neutral), these votes are purely consultative. The final decision is made by Wikipedia’s bureaucrats, a smaller group of highly trusted users. Bureaucrats evaluate the votes and comments to determine if there is a community consensus.
Bureaucrats base their decisions on:
- The proportion of supporting versus opposing votes.
- The reasons provided in comments for or against the candidate.
- The nominee’s overall behavior and contributions to the platform.
Even if a candidate receives a majority of support votes, their adminship can be denied if the bureaucrats believe the consensus is insufficient or if specific concerns are raised during the discussion.
The plot above shows the number of times an RfA (Request for Adminship) was either successful (positive) or unsuccessful (negative) as a function of the approval rate. While most RfAs with an approval rate above 80% are accepted, there is a noticeable overlap between the two distributions. This highlights that voting is never the decisive factor; the final decision relies heavily on the bureaucrats’ evaluation of the consensus and context.
Expectation and judgment of community over time
How did success rate evolve with time?
We can observe a significant decline in both the success rate of RfAs and the number of RfAs over time. In the early years (2003-2006), the success rate was notably high, even reaching 100% in 2003, despite a sharp increase in the number of RfAs. However, from 2007 onward, the success rate dropped below 50% and remained low, while the number of RfAs also steadily decreased.
By 2013, we see an interesting shift: the success rate begins to rise again, while the number of RfAs has reached its lowest point. This trend may suggest that stricter evaluation processes or changing community standards contributed to the decline in RfA success and participation over the years.
Do voter behaviors remain stable over time, or are there signs of shifting trends?
To analyze voter behavior trends over time, we focused on the 100 most active voters, defined by their total votes and participation in at least two years. Using the positivity ratio — the proportion of positive votes — we applied linear regression to classify trends as “More Lenient” (increasing positivity), “More Strict” (decreasing positivity), or “No Significant Change”.
The majority of voters showed no significant change, reflecting stable behavior. Meanwhile, 14 voters exhibited a more lenient trend, and only 3 became more strict. Testing larger samples, such as 150 or 200 voters, produced similar proportions, highlighting consistent overall patterns.
These results suggest that while most voters maintain stable behavior, a small minority exhibit meaningful shifts over time
Are some voters more influential ?
Understanding the admin score
The Admin Score is a tool designed to provide a quick overview of how “admin-worthy” a user is on Wikipedia. It evaluates various factors of user activity, each weighted by specific multipliers. Key factors include account age, edit count, participation in key activities like AFDs (Articles for Deletion) and AIV (Administrator Intervention Against Vandalism), and the use of edit summaries. Each factor is capped at 100. This score gives a simplified but insightful view of a user’s contributions and reliability as a potential administrator.
Below is the distribution of Admin Scores across users:
- The small peak around 100 is due to many accounts that have not made any edits on the English Wikipedia but have maxed out the 100-point cap for the account age factor.
- This peak highlights the limitation of the score in distinguishing between inactive users with old accounts and active contributors.
- Beyond this peak, the distribution reflects a more meaningful differentiation among active and engaged users.
The second graph presents two boxplots comparing the distribution of Admin Scores between users who were accepted as administrators and those who were rejected. The green box for the accepted group shows generally higher median scores and a broader distribution extending well above 800, with some values reaching close to the maximum possible score. This suggests that most successful candidates tend to have strong engagement metrics. In contrast, the red box for the rejected group is centered lower, indicating that their typical scores cluster closer to the mid-range and rarely approach the upper end.
Understanding power voters
We define power voters by inspiring ourselves from the matrix of co-occurence, widely used in NLP to capture contextual relationships and highlight word influence. We adapt this by interpreting the users as words and each voting session as a document. We call the sum of co-occurrence values for each user participation and we combine it with the admin score to obtain our power score. Thanks to this, we have a meaningful ranking of how much influence each user has exerted on the adminship voting sessions. Below is a table of the top 10.
| User | Participation | Admin Score | Power Score | Positive Vote Ratio | Average Polarity |
|---|---|---|---|---|---|
| Acalamari | 61987 | 1300.0 | 0.847 | 0.974 | 0.506 |
| Stifle | 57998 | 1297.0 | 0.824 | 0.629 | 0.092 |
| Siva1979 | 89307 | 827.0 | 0.818 | 0.850 | 0.451 |
| Bearian | 56537 | 1300.0 | 0.817 | 0.901 | 0.492 |
| Juliancolton | 41846 | 1277.0 | 0.725 | 0.788 | 0.365 |
| Malinaccier | 47010 | 1180.0 | 0.717 | 0.920 | 0.642 |
| SoWhy | 30145 | 1300.0 | 0.669 | 0.741 | 0.456 |
| Bibliomaniac15 | 31478 | 1279.0 | 0.668 | 0.930 | 0.421 |
| Daniel | 29806 | 1017.0 | 0.660 | 0.493 | 0.127 |
| Newyorkbrad | 47998 | 1282.0 | 0.660 | 0.819 | 0.463 |
Are power voters more strict?
To answer this, we explored the sentiment of the comments attached to each vote of all users that have voted in 4 or more different years. We also calculated how often they vote positively and combined all of the information in three plots:
Power Score and Positive Vote Ratio showed no significant correlation, although most people vote predominantly positively.
Power Score and Average Polarity are practically uncorrelated, which means that the amount of positivity/negativity in their comments does not depend on their rank.
Positive Vote Ratio and Average Polarity presented a correlation of 0.52. One possible interpretation would be that some of the people who tend to speak more positively, would only vote when they are supporting the adminship request and would abstain if they’re against.
Are users categorizable ?
To explore user activity and interests, we scraped and analyzed the top 10 most modified articles for each user. We categorized these articles into four categories per user using a predefined set of categories derived from Wikipedia. To assign the most relevant categories to each article, we leveraged a language model (LLM) that classified the content based on its themes.
To validate the accuracy of the assigned categories, we conducted a review on a subset of users. This analysis revealed that, in most cases, the first three categories assigned by the model aligned well with the themes of the articles. However, the fourth category often proved to be less relevant, suggesting that assigning four categories might have been excessive.
Categories distribution
The bar chart visualizes the distribution of users across these categories, showing that broad-interest areas like “History,” “Entertainment,” and “Culture” dominate. More specialized categories, such as “Universe” and “Energy,” have fewer users, reflecting their niche appeal. We also acknowledge that some categories may “eat each other,” as overlapping themes (e.g., “Culture” and “Society”) could group similar interests together. Despite this, the plot highlights the diversity of user interests and provides a clear view of how users contribute to different areas of knowledge within the community.
Outcomes by categories
We aimed to determine whether the category a user belongs to influences the RfA outcome. To explore this, we analyzed success and failure trends across categories by calculating the total number of successes and failures, as well as their respective success rates. Using a chi-square test for independence, we examined whether the distribution of outcomes varied significantly between categories. The stacked bar chart highlights raw counts, with successes dominating in categories like “Government”, “Sciences”, “Technology”, “Entertainment” and “Culture” while failures are more prevalent in others. The success rate chart complements this by providing a clearer percentage-based view, showcasing categories with consistently high success rates. The statistical test confirmed significant differences, reinforcing the idea that category-specific dynamics significantly impact outcomes. These findings also validate the coherence of our category labeling approach.
Mutual support
We investigated whether the level of support varies depending on whether a voter’s category matches the category being evaluated. For each category, we calculated support rates (percentage of positive votes) within the same category and compared them to support rates from voters in different categories. In most cases, voters from different categories tend to be stricter with each others than those within the same category. This suggests that evaluations from within a category may be leaner. These patterns provide insights into how community dynamics and categorical perspectives influence voting behavior.
Community detection
At the heart of Wikipedia is the community-based decision about who is eligible to become an administrator. For the final part of this study we will try to identify this community. For this purpose, an interaction network has been constructed based on the RFA data. Each node represents a user in the network, where the node size is proportional to the number of interactions (here votes in RFA). The edges represent the interactions between these users. Based on this graph, we then clustered each user into a community using the Louvain community detection method. The result is shown in the image below, where each community is represented by a colour.
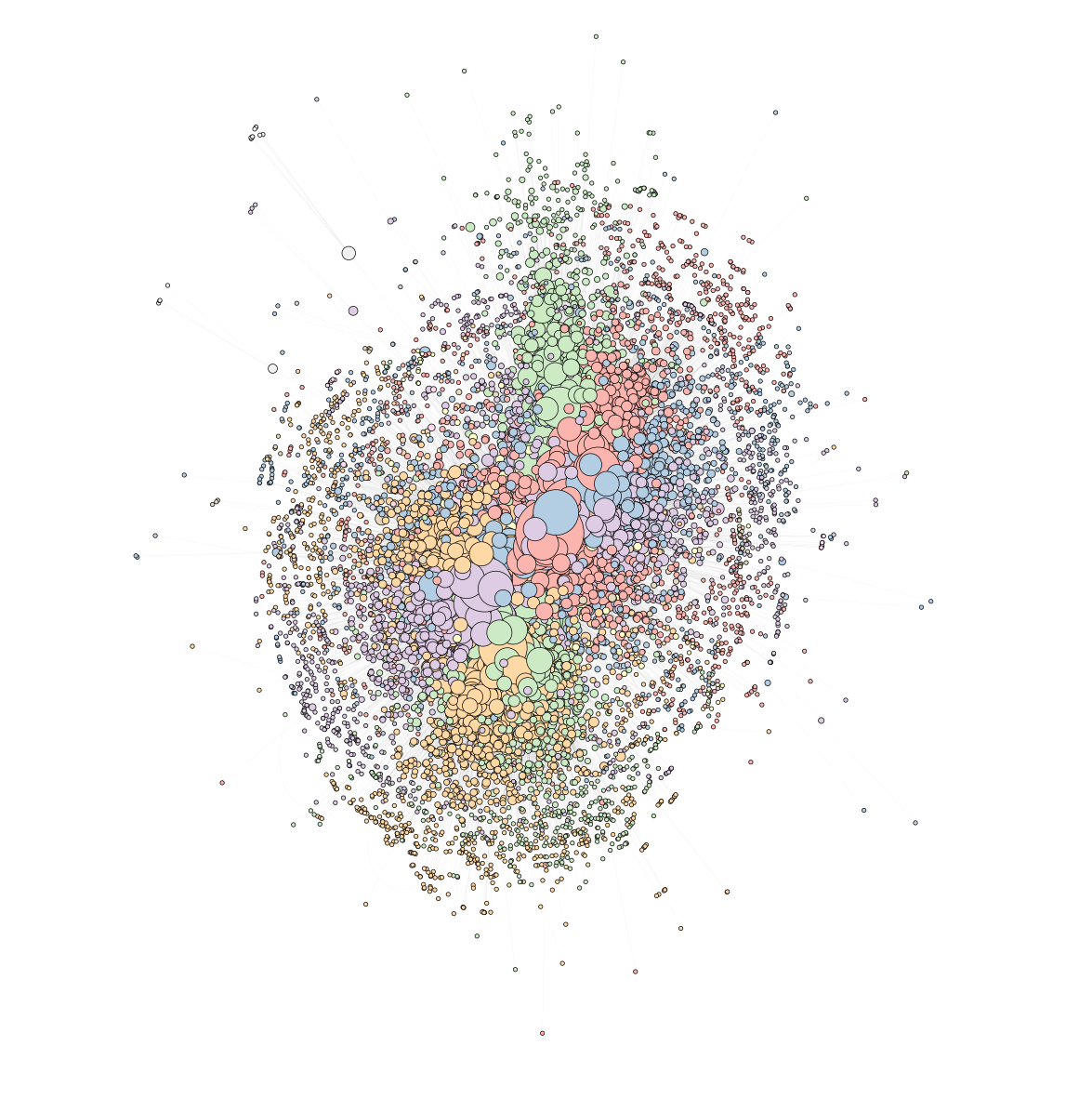
Using this method, we managed to extract 18 municipalities. The communities were then grouped in order to have a clearer visualisation. The size of the nodes represents the number of users within a community and the thickness of the edge represents the number of interactions between communities. The aim is then to study the distribution of each user’s categories and their admin score within a community. To do this, we compute the percentage of users who have the same category in their four attached categories. The three most common categories within a community are displayed. We also calculate the average admin score within a community. The result is shown in the interactive community graph below.
Looking at the community graph, there are several interesting things to note. Firstly, in the central communities (which are also the largest), the main categories represented are always history, entertainment and culture. This observation is consistent with the distribution of categories we saw earlier. For small, marginal communities, however, the picture is more interesting. For example, there is a group of 10 geographers in the bottom right corner (community 18) and a group of 56 scientists in the top right corner (community 14). As for the admin score, small groups tend to have lower admin scores, with the exception of community 12, which seems to work hard on geography issues. The best is community 10 with an average admin score of 737 for 1105 people.
Conclusion
We end up with an interesting result when we combine the results of our analysis. Based only on the RAF dataset and especially the usernames, we collect as much information as possible. A nice collection of data has been built, containing voting records, user attributes and community structures for each user. Using this as a baseline, we were able to highlight several trends, such as the declining success rates of RfAs over time, strong concentration in broad interest topics like history, culture and entertainment, communities and power voter detection. The study we conducted provides valuable insights that could significantly benefit Wikipedia’s hierarchical structure. For example, our community analysis highlights the importance of encouraging engagement in smaller, specialised groups, which could be used to diversify and strengthen Wikipedia’s administrative core. It represents a milestone in the quest to improve the transparency, fairness and effectiveness of the RfA process.
To conclude this study of Wikipedia’s administrative application process, we would like to emphasise the importance of remaining critical of our findings. The main difficulty was probably in finding power voters and in accurately finding some communities based on our information. Indeed, even when we arrive at some results, it is still difficult to assess whether they are representative of reality. Because of the limited amount of information available, these processes only capture a subset of the complex interaction in the real world for a community platform like wikipedia. Considering only one aspect of a complex whole can lead to inaccuracies and even biases in the conclusions we draw.
References
-
XTool, Feeding your data hunger, 2008-2024, v.3.20.3,
https://xtools.wmcloud.org/ -
Ollama, Llama3.1 (8b), https://ollama.com/library/llama3.1
-
NeworkX, louvain_communities, 2004-2024, NetworkX Developers,
https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.community.louvain.louvain_communities.html -
Wikipedia:Contents/Categories, 12 April 2021,
https://en.wikipedia.org/wiki/Wikipedia:Contents/Categories